---
title: "Hairmonics - schizofrenie"
---
```{r}
#| include: false
library(tidyverse)
library(brms)
library(tidybayes)
library(cmdstanr)
library(glue)
library(forcats)
library(stringr)
library(ggridges)
library(posterior)
library(tidytext)
library(gt)
library(ggnewscale)
library(stringr)
library(latex2exp)
library(ggforce)
library(readxl)
library(kableExtra)
sigfig <- function(vec, n=3){
### function to round values to N significant digits
# input: vec vector of numeric
# n integer is the required sigfig
# output: outvec vector of numeric rounded to N sigfig
formatC(signif(vec,digits=n), digits=n,format="fg", flag="#")
}
theme_set(theme_ggdist())
theme_update(text = element_text(size = 15),
plot.subtitle=element_text(hjust=0.5))
# path <- cmdstanr::cmdstan_path()
# set_cmdstan_path(path = "C:/Users/Lynx/.cmdstan/cmdstan-2.36.0")
set_cmdstan_path(path = Sys.getenv("CMDSTAN_PATH"))
knitr::knit_engines$set(
stan = function(options) {
code <- knitr:::one_string(options$code)
out <- options$output.var
if (!is.character(out) || length(out) != 1L) stop(
"the chunk option output.var must be a character string ",
"providing a name for the returned `CmdStanModel` object."
)
if (options$eval) {
if (options$cache) {
cache_path <- knitr:::valid_path(
options[["cache.path"]],
options$label
)
if (!dir.exists(cache_path)) {
dir.create(cache_path)
}
model_file <- tempfile(
fileext = ".stan",
tmpdir = cache_path
)
cat(code, "\n", file = model_file)
} else {
model_file <- write_stan_file(code)
}
csm <- cmdstan_model(model_file)
assign(out, csm, envir = knit_global())
}
engine_output(options, code, '')
}
)
```
```{r}
#| include: false
hairmonics0 <- read_xlsx("D:/workR/Projects/AZV HCC/HAIRMONICS_vysledky2.xlsx",
skip = 1, sheet = 1, range = )
hairmonics_date <- hairmonics0 %>%
janitor::clean_names() %>%
select(kod, contains("_datum")) %>%
pivot_longer(-kod, names_to = "visit", values_to = "date",
names_pattern = "(..)")
hairmonics <- hairmonics0 %>%
janitor::clean_names() %>%
select(kod, matches("_\\d.cm$")) %>%
mutate(across(-kod, as.numeric)) %>%
# mutate(v2_v1_diff = interval(v2_datum_odberu, v1_datum_odberu) %>% as.numeric("months"),
# fu_v1_diff = interval(fu_datum_odberu, v1_datum_odberu) %>% as.numeric("months"),
# fu_v2_diff = interval(fu_datum_odberu, v2_datum_odberu) %>% as.numeric("months"),
# ) %>%
pivot_longer(matches("_\\d.cm$"), names_to = c("visit", "segment"), values_to = "HCC",
names_pattern = "(.*)_(\\d)",
names_transform = list(visit = as.factor, segment = as.numeric)) %>%
left_join(hairmonics_date, by = c("kod", "visit")) %>%
mutate(visit = factor(visit, levels = c("v1", "v2", "fu"))) %>%
filter(!is.na(date)) %>%
group_by(kod) %>%
mutate(date_diff = interval(max(date, na.rm = TRUE), date) %>% as.numeric('months'),
date_total = date_diff - segment,
HCC0 = HCC / exp(-0.15 * segment)) %>%
filter(!is.na(HCC)) %>%
# filter(!is.na(date_total)) %>%
ungroup()
paired_tbl <- tibble::tribble(
~kod, ~MP, ~group,
"H-VX2J9", 1L, 1L,
"H-MNQKU", 2L, 1L,
"H-XBZML", 3L, 1L,
"H-YQNM8", 4L, 1L,
"H-5YZ7J", 5L, 1L,
"H-VKUTZ", 6L, 1L,
"H-YXAWC", 7L, 1L,
"H-LVHKD", 8L, 1L,
"H-42MDQ", 9L, 1L,
"H-HJTDL", 10L, 1L,
"H-YP8YL", 11L, 1L,
"H-KLA3B", 12L, 1L,
"H-7X4FA", 13L, 1L,
"H-Z7BDS", 14L, 1L,
"H-MQJVT", 15L, 1L,
"H-EMB9H", 16L, 1L,
"H-SAHXJ", 17L, 1L,
"H-T9CWS", 18L, 1L,
"H-HZJKQ", 19L, 1L,
"H-AKWNE", 20L, 1L,
"H-AK4B5", 21L, 1L,
"H-TPFT7", 22L, 1L,
"H-EAVUF", 23L, 1L,
"H-UF3FZ", 24L, 1L,
"H-J89CL", 25L, 1L,
"H-A5TXM", 26L, 1L,
"H-L32SM", 27L, 1L,
"H-KN3N4", 28L, 1L,
"H-B8CLN", 29L, 1L,
"H-J2K8C", 30L, 1L,
"H-WBFF9", 31L, 1L,
"H-97EUD", 1L, 2L,
"H-RXXCP", 2L, 2L,
"H-AZ875", 3L, 2L,
"H-DTWDE", 4L, 2L,
"H-QJW45", 5L, 2L,
"H-Z9ZJP", 6L, 2L,
"H-TJKW7", 7L, 2L,
"H-X8PLF", 8L, 2L,
"H-MKQRM", 9L, 2L,
"H-7BZJY", 10L, 2L,
"H-LH32A", 11L, 2L,
"H-3THVA", 12L, 2L,
"H-JCPCY", 13L, 2L,
"H-8AK95", 14L, 2L,
"H-SWYHX", 15L, 2L,
"H-9S2VL", 16L, 2L,
"H-2A3N2", 17L, 2L,
"H-WSV22", 18L, 2L,
"H-75452", 19L, 2L,
"H-CVD2K", 20L, 2L,
"H-BS5WS", 21L, 2L,
"H-PD5CK", 22L, 2L,
"H-37HTF", 23L, 2L,
"H-KTX5V", 24L, 2L,
"H-7LXNL", 25L, 2L,
"H-XHWLF", 26L, 2L,
"H-5Z8WA", 27L, 2L,
"H-KQN9N", 28L, 2L,
"H-SD3J8", 29L, 2L,
"H-KMS7H", 30L, 2L,
"H-H79F8", 31L, 2L
)
hairmonics_SCHZ <- hairmonics %>%
group_by(kod) %>%
right_join(paired_tbl, by = "kod") %>%
mutate(group = as.factor(group),
MP = as.factor(MP)) %>%
filter(HCC > 0) %>%
ungroup()
hairmonics_SCHZ_v1 <- hairmonics_SCHZ %>%
filter((group == 2 & visit == "v1") | (group == 1 & visit == "v1"))
```
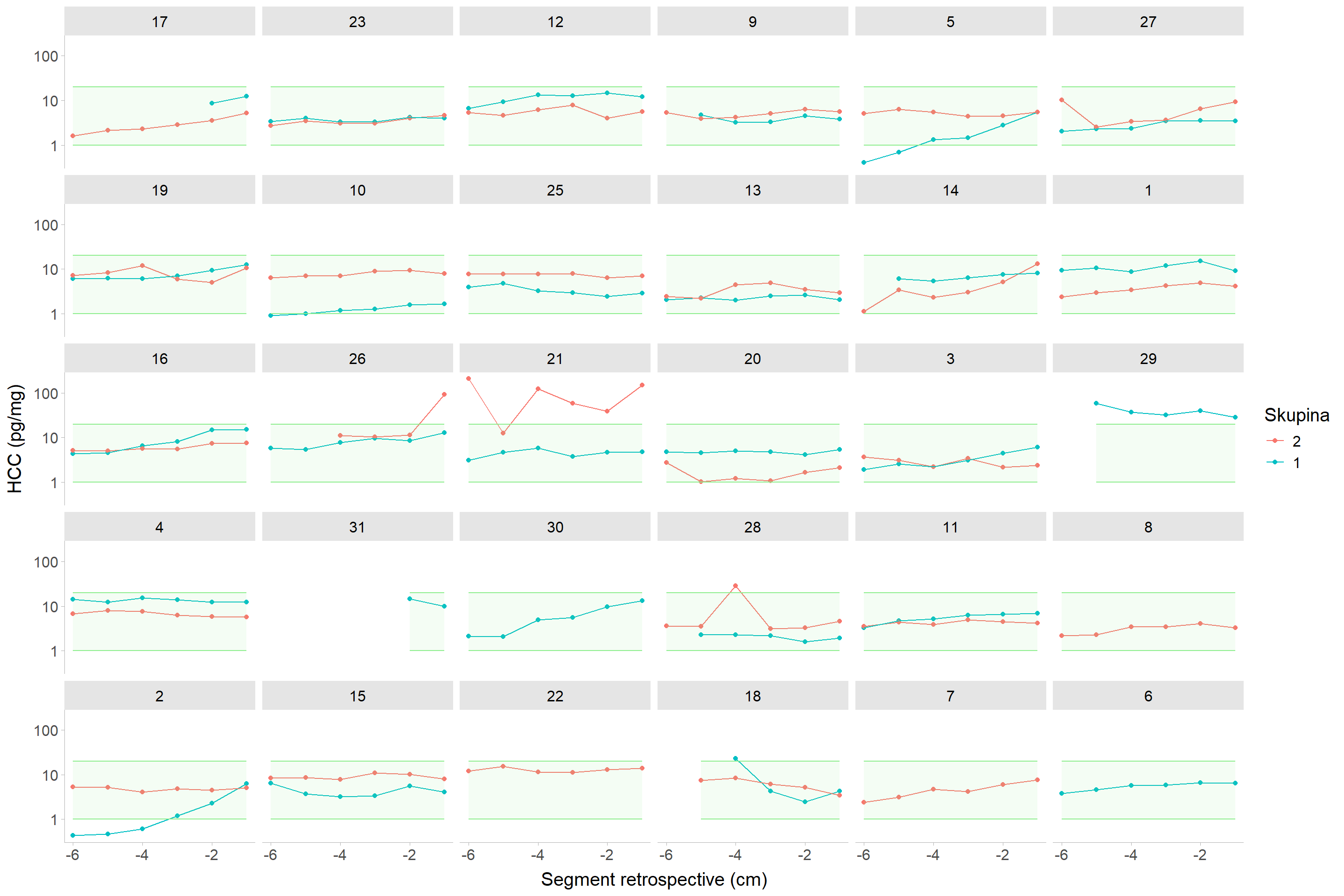
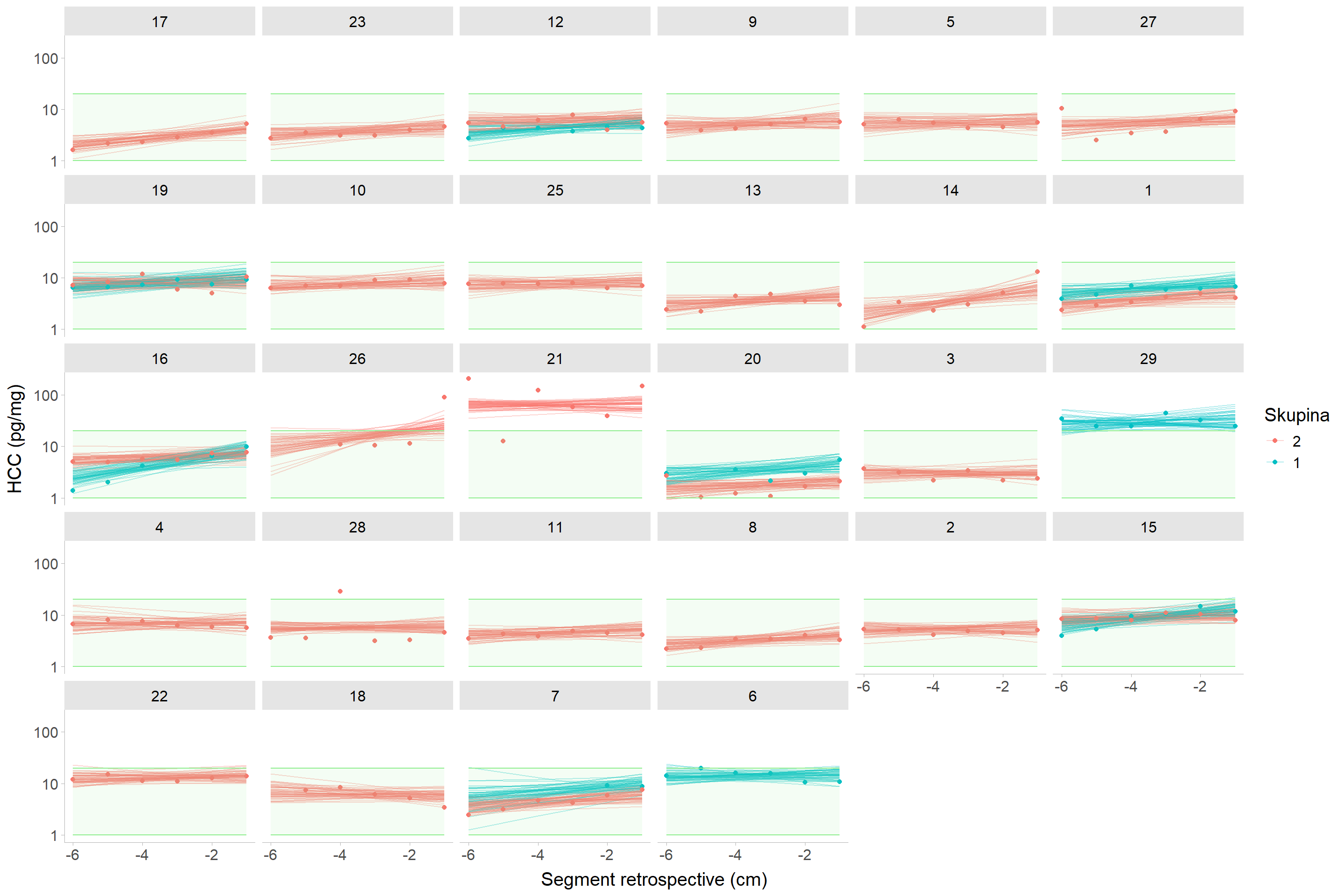
#### Schizofrenie (v1) vs. kontrola (v1) u párovaných jedinců
Díky párovaným jedincům je možné zobrazit porovnání skupin schizofrenie vs. kontroly jako segmentovaný vlasový kortizol (@fig-fig1). I bez použití modelu je zřejmé, že se skupiny nejenže mezi sebou neliší relativně, ale také nevybočují z absolutního (námi) udávaného referenčního rozmezí 1--20 pg/mg.
```{r}
#| label: "fig-fig1"
#| fig-cap: "Nekorigovaný vlasový kortizol u spárovaných jedinců skupin schizofreniků (v1) a kontrol z první návštěvy (v1). Zelený obdélník představuje rozmezí hodnot 1 -- 20 pg/mg."
hairmonics_SCHZ %>%
filter((group == 2 & visit == "v1") | (group == 1 & visit == "v1")) %>%
ggplot(aes(-segment, HCC, color = group)) +
geom_point() +
geom_line(aes(group = kod)) +
geom_ribbon(aes(ymax = 20, ymin = 1), alpha = 0.1, fill = "lightgreen", color = "lightgreen") +
scale_y_log10() +
facet_wrap(~MP, scales = "fixed") +
labs(x = "Segment retrospective (cm)",
y = "HCC (pg/mg)",
color = "Skupina")
```
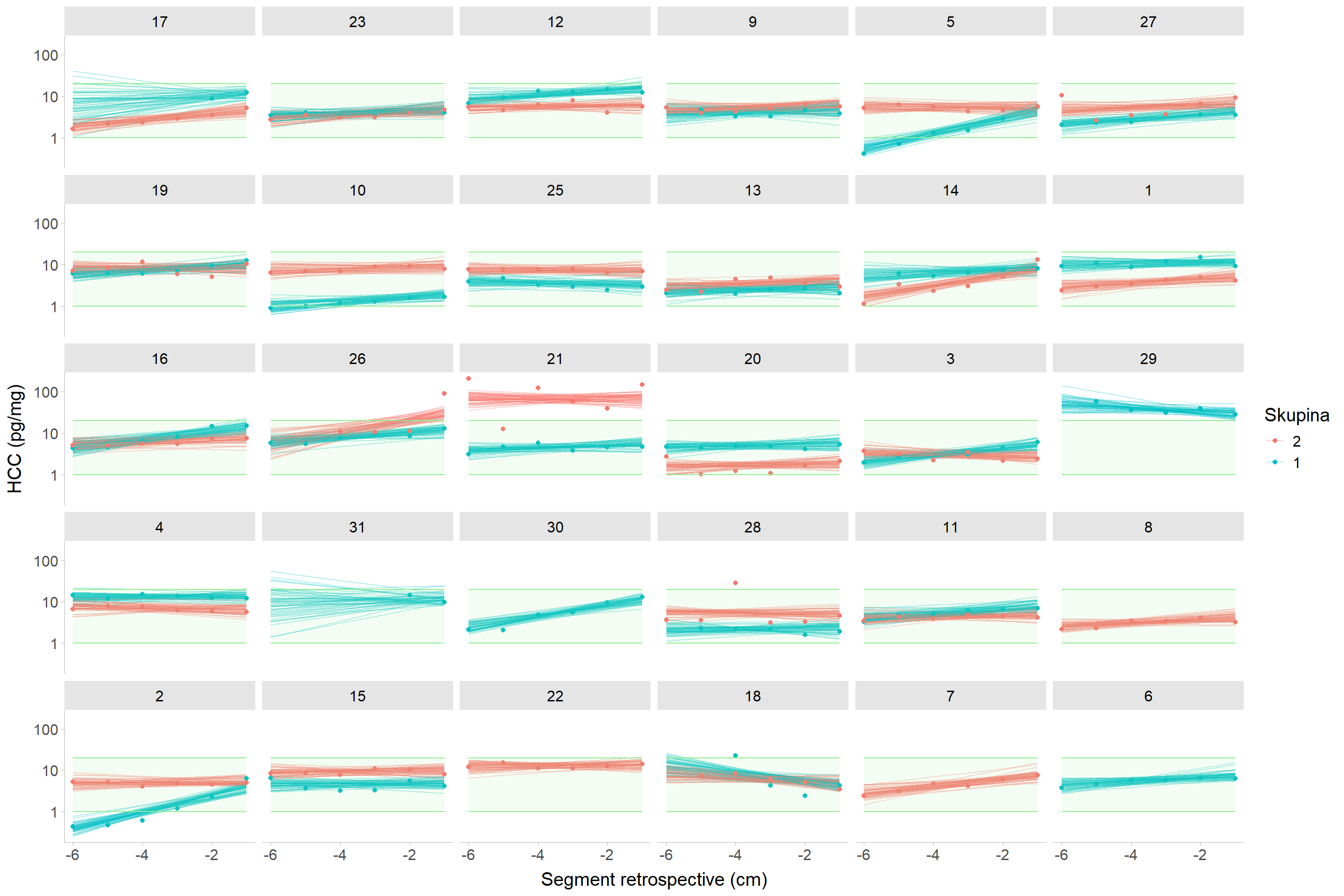
Pro modelování se tedy nabízí dvě struktury:
1) HCC ~ 1 + segment * group + (1 + segment | kod)
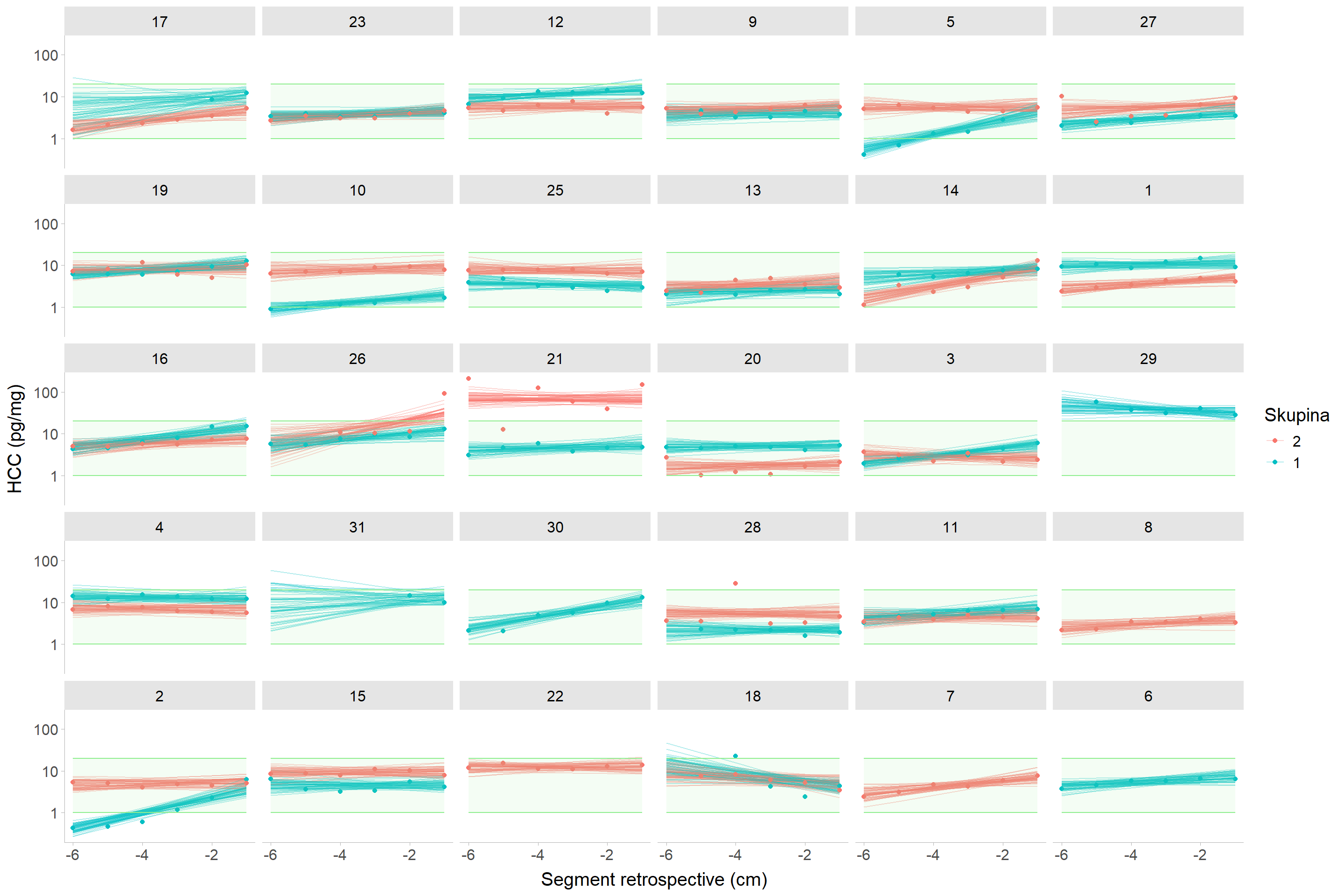
2) HCC ~ 1 + segment * group + (1 + segment | MP) + (1 + segment | MP:kod)
Model 2) zohledňuje párový design jednotlivých dvojic (kontrola -- pacient) a umožňuje oddělit variabilitu jedinců (ID) od variability párů (MP).
Proč tedy modelovat i ten první model? Protože chceme vědět, jak moc párový design pomůže do sebe vstřebat variabilitu mezi jedinci. Pokud mezi 1) a 2) nebude dramatický rozdíl, lze říci, že model 1) je plně dostačující a párový design nepřináší žádnou informaci navíc.
```{r}
#| include: false
br_mp <- brm(HCC ~ segment * group + (1 + segment | kod),
family = "lognormal",
cores = 4,
data = hairmonics_SCHZ_v1,
backend = "cmdstanr")
summary(br_mp)
# conditional_effects(br_mp)
br_mp2 <- brm(HCC ~ segment * group + (1 + segment | MP/kod),
family = "lognormal",
cores = 4,
data = hairmonics_SCHZ_v1,
backend = "cmdstanr")
summary(br_mp2)
conditional_effects(br_mp2)
mp_loo <- add_criterion(br_mp, "loo")
mp2_loo <- add_criterion(br_mp2, "loo")
loo_compare(mp_loo, mp2_loo)
```
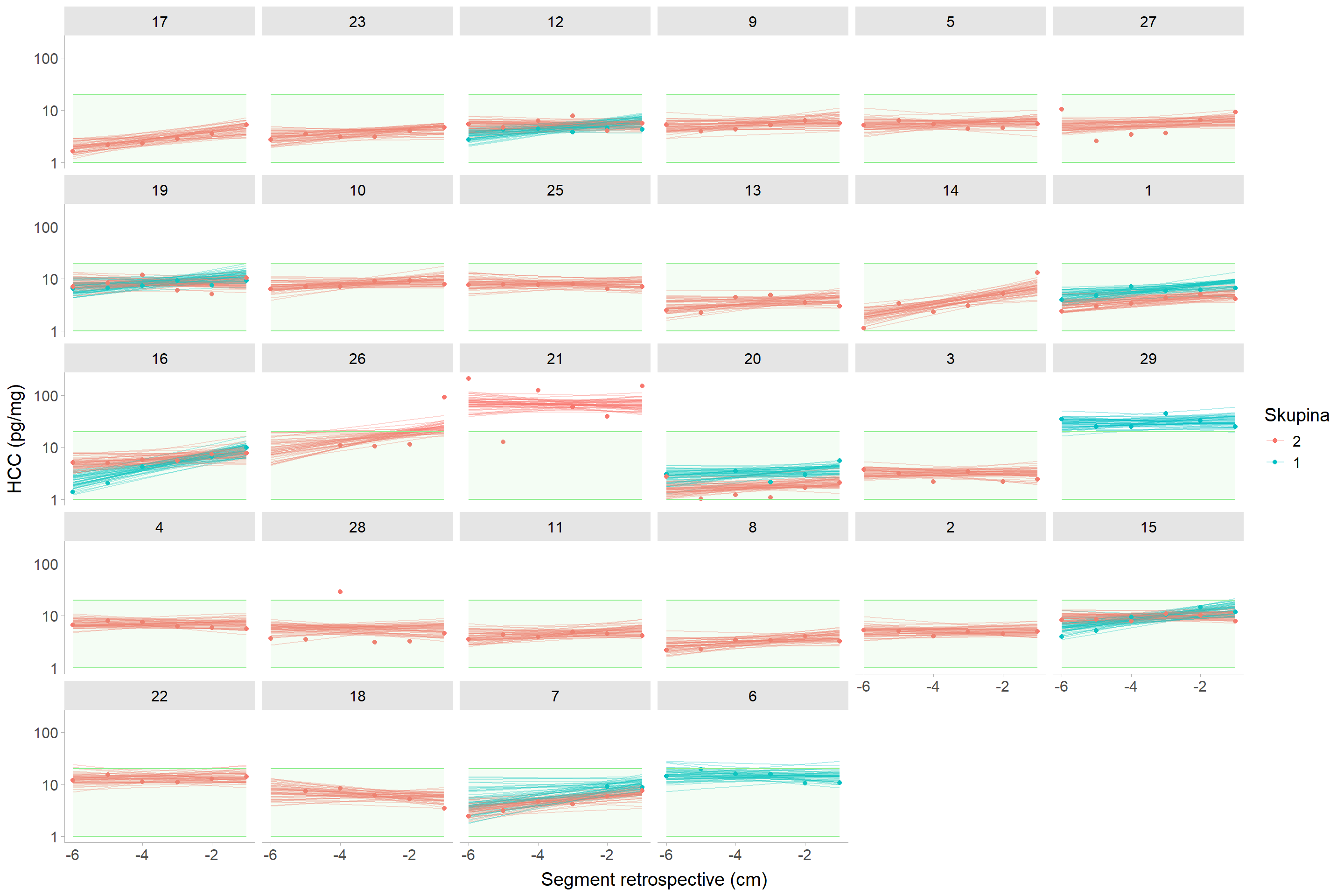
```{r}
#| label: "fig-fig_mp"
#| fig-cap: "Nekorigovaný vlasový kortizol modelovaný jako nepárová varianta (model 1) jedinců skupin schizofreniků (v1) a kontrol z první návštěvy (v1). Zelený obdélník představuje rozmezí hodnot 1 -- 20 pg/mg."
hairmonics_SCHZ_v1 %>%
expand(segment = 1:6, nesting(MP, group, kod)) %>%
add_epred_draws(br_mp, ndraws = 50, allow_new_levels = TRUE) %>%
ggplot(aes(-segment, HCC, color = group)) +
geom_line(aes(y = .epred, group = paste(.draw, kod)), alpha = 0.3) +
geom_point(data = hairmonics_SCHZ_v1) +
geom_ribbon(aes(ymax = 20, ymin = 1), alpha = 0.1, fill = "lightgreen", color = "lightgreen",
data = hairmonics_SCHZ_v1 %>%
expand(segment = 1:6, nesting(MP, group, kod, HCC))) +
scale_y_log10() +
facet_wrap(~MP, scales = "fixed") +
labs(x = "Segment retrospective (cm)",
y = "HCC (pg/mg)",
color = "Skupina")
```
```{r}
#| label: "fig-fig_mp2"
#| fig-cap: "Nekorigovaný vlasový kortizol modelovaný jako párová varianta (model 2) jedinců skupin schizofreniků (v1) a kontrol z první návštěvy (v1). Zelený obdélník představuje rozmezí hodnot 1 -- 20 pg/mg."
hairmonics_SCHZ_v1 %>%
expand(segment = 1:6, nesting(MP, group, kod)) %>%
add_epred_draws(br_mp2, ndraws = 50, allow_new_levels = TRUE) %>%
ggplot(aes(-segment, HCC, color = group)) +
geom_line(aes(y = .epred, group = paste(.draw, kod)), alpha = 0.3) +
geom_point(data = hairmonics_SCHZ_v1) +
geom_ribbon(aes(ymax = 20, ymin = 1), alpha = 0.1, fill = "lightgreen", color = "lightgreen",
data = hairmonics_SCHZ_v1 %>%
expand(segment = 1:6, nesting(MP, group, kod, HCC))) +
scale_y_log10() +
facet_wrap(~MP, scales = "fixed") +
labs(x = "Segment retrospective (cm)",
y = "HCC (pg/mg)",
color = "Skupina")
```
Model 1)
```{r}
summary(br_mp)
```
Model 2)
```{r}
summary(br_mp2)
```
Prakticky lze říci, že párový design nedokáže lépe oddělit variabilitu mezi jedinci do variability párů.
#### Schizofrenie (fu) vs. kontrola (v1) u párovaných jedinců
Přestože kontroly mají pouze jeden odběr vlasů v době první návštěvy, tak je možné (a i vhodné) porovnat tytéž páry jedinců jako možné rozdíly mezi v1 kontrola a follow-up (fu) pacientů, viz @fig-fig2.
```{r}
#| label: "fig-fig2"
#| fig-cap: "Nekorigovaný vlasový kortizol u spárovaných jedinců skupin schizofreniků (fu) a kontrol z první návštěvy (v1). Zelený obdélník představuje rozmezí hodnot 1 -- 20 pg/mg."
hairmonics_SCHZ %>%
filter((group == 2 & visit == "v1") | (group == 1 & visit == "fu")) %>%
ggplot(aes(-segment, HCC, color = group)) +
geom_point() +
geom_line(aes(group = kod)) +
geom_ribbon(aes(ymax = 20, ymin = 1), alpha = 0.1, fill = "lightgreen", color = "lightgreen") +
scale_y_log10() +
facet_wrap(~MP, scales = "fixed") +
labs(x = "Segment retrospective (cm)",
y = "HCC (pg/mg)",
color = "Skupina")
```
V tomto případě je dat ještě méně, ale opět nijak nevybočují z řady. Při porovnání průměrných změn, které mají skupiny párovaných jedinců v době první návštěvy - tedy rozdíl $E[HCC_1^{v1} - HCC_2^{v1}]$ a $E[HCC_1^{fu} - HCC_2^{v1}]$, obdržíme vlastně rozdíl mezi $E[HCC_1^{fu} - HCC_1^{v1}]$, ovšem s hierarchickým zapojením jednotlivých párů.
```{r}
#| include: false
hairmonics_SCHZ_fu <- hairmonics_SCHZ %>%
filter((group == 2 & visit == "v1") | (group == 1 & visit == "fu"))
br_mp_fu <- brm(HCC ~ segment * group + (1 + segment | kod),
family = "lognormal",
cores = 4,
data = hairmonics_SCHZ_fu,
backend = "cmdstanr")
summary(br_mp_fu)
# conditional_effects(br_mp_fu)
br_mp_fu2 <- brm(HCC ~ segment * group + (1 + segment | MP/kod),
family = "lognormal",
cores = 4,
data = hairmonics_SCHZ_fu,
backend = "cmdstanr")
summary(br_mp_fu2)
# conditional_effects(br_mp_fu2)
mp_fu_loo <- add_criterion(br_mp_fu, "loo")
mp_fu2_loo <- add_criterion(br_mp_fu2, "loo")
loo_compare(mp_fu_loo, mp_fu2_loo)
```
```{r}
#| label: "fig-fig_mp_fu"
#| fig-cap: "Nekorigovaný vlasový kortizol modelovaný jako nepárová varianta (model 1) jedinců skupin schizofreniků (fu) a kontrol z první návštěvy (v1). Zelený obdélník představuje rozmezí hodnot 1 -- 20 pg/mg."
hairmonics_SCHZ_fu %>%
expand(segment = 1:6, nesting(MP, group, kod)) %>%
add_epred_draws(br_mp_fu, ndraws = 50, allow_new_levels = TRUE) %>%
ggplot(aes(-segment, HCC, color = group)) +
geom_line(aes(y = .epred, group = paste(.draw, kod)), alpha = 0.3) +
geom_point(data = hairmonics_SCHZ_fu) +
geom_ribbon(aes(ymax = 20, ymin = 1), alpha = 0.1, fill = "lightgreen", color = "lightgreen",
data = hairmonics_SCHZ_fu %>%
expand(segment = 1:6, nesting(MP, group, kod, HCC))) +
scale_y_log10() +
facet_wrap(~MP, scales = "fixed") +
labs(x = "Segment retrospective (cm)",
y = "HCC (pg/mg)",
color = "Skupina")
```
```{r}
#| label: "fig-fig_mp_fu2"
#| fig-cap: "Nekorigovaný vlasový kortizol modelovaný jako párová varianta (model 2) jedinců skupin schizofreniků (fu) a kontrol z první návštěvy (v1). Zelený obdélník představuje rozmezí hodnot 1 -- 20 pg/mg."
hairmonics_SCHZ_fu %>%
expand(segment = 1:6, nesting(MP, group, kod)) %>%
add_epred_draws(br_mp_fu2, ndraws = 50, allow_new_levels = TRUE) %>%
ggplot(aes(-segment, HCC, color = group)) +
geom_line(aes(y = .epred, group = paste(.draw, kod)), alpha = 0.3) +
geom_point(data = hairmonics_SCHZ_fu) +
geom_ribbon(aes(ymax = 20, ymin = 1), alpha = 0.1, fill = "lightgreen", color = "lightgreen",
data = hairmonics_SCHZ_fu %>%
expand(segment = 1:6, nesting(MP, group, kod, HCC))) +
scale_y_log10() +
facet_wrap(~MP, scales = "fixed") +
labs(x = "Segment retrospective (cm)",
y = "HCC (pg/mg)",
color = "Skupina")
```
Každopádně závěrem lze asi říct, že v rámci schizofrenie lze pozorovat minimální až žádné rozdíly mezi skupinami bez ohledu na to, zda-li je využit párový design. Zajímavé by bylo toto stejné provést pro další kohorty pacientů, ale ty nejsou ještě označené v tabulce Hairmonics.